Trie (arbore de prefixe)
Ce este un Trie
Un trie (sau arbore de prefixe) este un arbore de căutare -ar (un arbore cu rădăcină unde fiecare nod are maxim fii), reprezentând un mod unic de a memora informațiile, numite și chei.
Numărul de fii al unui nod este în mare parte influențat de tipul informațiilor memorate, dar de cele mai multe ori, un Trie este folosit pentru reținerea șirurilor de caractere, astfel fiecare nod având maxim 26 fii.
Inițial arborele conține doar un singur nod, rădăcina, urmând ca apoi cuvintele să fie introduse în ordinea citirii lor, de la stânga la dreapta. Observăm că înălțimea arborelui este lungimea maximă a unui cuvânt. Complexitatea de timp este , unde este lungimea maximă, iar memoria consumată, în cel mai rău caz, este .
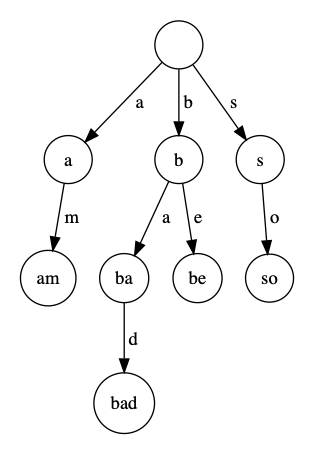
Un exemplu de trie pentru cuvintele am, bad, be și so
Moduri de implementare
Există două modalități standard prin care putem implementa un Trie, folosind pointeri sau vectori. Ambele funcționează la fel de bine, însă operația de delete este mai greu de implementat cu vectori.
Prin pointeri
Ne vom folosi de o structură unde vom reține un contor reprezentând de câte ori am trecut prin nodul curent, cât și un vector de pointeri, reprezentând fiii nodului curent.
struct Trie {
int cnt;
Trie *fii[26];
Trie() : cnt{0} {
for (int i = 0; i < 26; ++i) {
fii[i] = nullptr;
}
}
~Trie() {
for (int i = 0; i < 26; ++i) {
delete fii[i];
}
}
};
Trie *root = new Trie;Operația de insert poate fi foarte ușor scrisă recursiv.
void insert(Trie *node, string a, int poz) {
if (poz == a.size()) {
node->cnt++;
return;
}
int index = a[poz] - 'a';
if (node->fii[index] == nullptr) {
node->fii[index] = new Trie();
}
insert(node->fii[index], a, poz + 1);
}În momentul în care am ajuns la un nod în arbore, verificăm dacă există fiul pentru caracterul următor și dacă nu există, îl adăugăm în arbore, apoi apelăm recursiv până ajungem la finalul stringului.
Pentru a elimina un string din trie ne mai trebuie o informație suplimentară, și anume să știm câți fii are un nod. Așadar, dacă am eliminat un sufix al șirului și nodul curent nu mai are fii nici nu mai este vizitat prin alt șir inserat, putem da erase complet la pointerul respectiv.
bool del(Trie *node, string a, int pos) {
int idx = a[pos] - 'a';
if (pos == a.size()) {
node->cnt--;
} else if (del(node->fii[idx], a, pos + 1)) {
node->nrf--;
node->fii[idx] = nullptr;
}
if (node->cnt == 0 && node->nrf == 0 && node != t) {
delete node;
return 1;
}
return 0;
}Restul operațiilor se implementează similar, practic baza tuturor operațiilor stă în modul de a parcurge trie-ul.
Prin vectori
În loc de o structură vom folosi un vector cu coloane. În fiecare element din vector vom reține poziția fiului respectiv.
vector<vector<int>> trie(1, vector<int>(26, -1));Astfel trie[node][5] va fi egal cu poziția în vectorul trie pentru al cincilea fiu a lui node.
Operația de inserare este foarte similară față de cea precedentă, singurul lucru care diferă este modul de implementare. În acest caz ne este mult mai ușor să folosim o funcție care să itereze propriu-zis prin șirul de caractere.
vector<vector<int>> trie(1, vector<int>(26, -1));
vector<int> cnt(1);
void insert(string a) {
int root = 0;
for (const char i : a) {
int idx = i - 'a';
if (trie[root][idx] == -1) {
trie[root][idx] = trie.size();
trie.emplace_back(26, -1);
cnt.push_back(0);
}
cnt[root]++;
root = trie[root][idx];
}
cnt[root]++;
}Observăm faptul că incrementăm și la final contorul.
Trie pe biți
Unele probleme necesită reținerea numerelor într-o structură de date, cum ar fi un trie, însa vom înlocui șirurile de caractere cu reprezentarea binară a numerelor.
Problema xormax de pe Kilonova (ușoară)
Un exemplu bun este chiar problema xormax, unde ni se dă un vector cu elemente și trebuie să aflăm care este suma xor maximă a unui interval. Suma xor a unui interval cu capetele este valoarea , unde este operatorul xor pe biți.
Pentru a rezolva problema putem parcurge vectorul de la stânga la dreapta și să aflam pentru fiecare care este suma xor maximă a unui interval care se termină în . Dacă construim vectorul , unde , atunci suma xor pe intervalul este egală cu . Observăm că pentru un fixat trebuie să găsim care este -ul care maximizează relația de mai sus. Pentru a face asta putem să introducem primii -uri într-un trie pe biți și să căutăm bit cu bit, începând cu bitul semnificativ, -ul care va maximiza rezultatul.
#include <iostream>
#include <vector>
using namespace std;
const int N = 2e5 + 1;
vector<vector<int>> trie(1, vector<int>(2, -1));
int n, v[N], xp[N];
int find(int nr) {
int root = 0;
int ans = 0;
for (int bit = 31; bit >= 0; bit--) {
bool b = (nr & (1 << bit));
if (trie[root][!b] == -1) {
if (trie[root][b] == -1) {
return ans;
} else {
root = trie[root][b];
}
} else {
ans += (1 << bit);
root = trie[root][!b];
}
}
return ans;
}
void insert(int nr) {
int root = 0;
for (int bit = 31; bit >= 0; bit--) {
bool b = (nr & (1 << bit));
if (trie[root][b] == -1) {
trie[root][b] = trie.size();
trie.emplace_back(2, -1);
}
root = trie[root][b];
}
}
int main() {
cin.tie(nullptr)->sync_with_stdio(nullptr);
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> v[i];
xp[i] = xp[i - 1] ^ v[i];
}
int ans = 0;
insert(0);
for (int i = 1; i <= n; i++) {
int res = find(xp[i]);
ans = max(ans, res);
insert(xp[i]);
}
cout << ans;
}O variantă care se folosește de implementarea cu pointeri este următoarea:
#include <iostream>
#include <vector>
using namespace std;
struct Trie {
Trie *_next[2];
int _pos;
explicit Trie(const int value) : _pos{value}, _next{nullptr, nullptr} {}
Trie() : Trie{-1} {}
~Trie() {
delete _next[0];
delete _next[1];
}
} *root;
void add(const int val, const int idx) {
Trie *node = root;
for (int i = 29; i >= 0; i--) {
bool has = (val >> i) & 1;
if (node->_next[has] == nullptr) {
node->_next[has] = new Trie(idx);
}
node = node->_next[has];
}
}
int query(const int val) {
Trie *node = root;
for (int i = 29; i >= 0; i--) {
bool has = (val >> i) & 1;
if (node->_next[!has]) {
node = node->_next[!has];
} else if (node->_next[has]) {
node = node->_next[has];
} else {
break;
}
}
return node->_pos;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
root = new Trie(0);
int n, x, sum = 0, value = 0;
cin >> n;
vector<int> sums(n + 1);
add(sum, 0);
for (int i = 1; i <= n; i++) {
cin >> x;
sum ^= x;
sums[i] = sum;
value = max(value, x);
if (i > 1) {
int qry = query(sum);
value = max(value, sum ^ sums[qry]);
}
add(sum, i);
}
cout << value;
delete root;
return 0;
}Problema XOR Construction
În această problemă ni se dau numere, unde al -lea are valoarea , iar noi trebuie să construim alt vector , cu elemente, astfel încât să existe toate numerele de la 0 la în , iar .
În primul rând, dacă atunci , , deci și . Prin urmare deducem o formă generală pentru , unde , și anume . Proprietatea se respectă și pentru oricare , avem .
În al doilea rând, enunțul problemei asigură faptul că mereu va exista soluție. Dar când nu avem soluție? Păi în momentul în care se repetă două elemente în vectorul , ceea ce înseamnă faptul că trebuie să existe o secvență cu suma xor egală cu 0. Pentru simplitate vom spune că pe poziția va fi . Dacă și și , atunci , analog pentru . Dacă și atunci , . Prin urmare . Așadar, știm ca mereu în vectorul elementele vor fi distincte.
În al treilea rând, observăm că vectorul este generat în funcție de ce valoare are . Deci o primă idee ar fi să fixăm mai întâi unde vom pune 0-ul în vectorul și să-l construim în , complexitatea temporală fiind . Dar putem să ne folosim de a doua observație, și anume că mereu vectorul va avea elementele distincte. Deci ne este suficient să știm care va fi valoarea maximă din dacă 0-ul se află pe poziția . Pentru a face asta putem să folosim 2 trie-uri, unul pentru sufix, altul pentru prefix, complexitatea finală devenind .
#include <iostream>
#include <vector>
using namespace std;
const int N = 2e5 + 1;
int n;
vector<int> v(N), ans(N);
vector<int> xr1(N), xr2(N);
vector<vector<int>> trie1(1, vector<int>(2, -1)), trie2(1, vector<int>(2, -1));
vector<int> maxim1(N), maxim2(N);
void insert(vector<vector<int>> &trie, int nr) {
int root = 0;
for (int i = 30; i >= 0; i--) {
bool bit = (nr & (1 << i));
if (trie[root][bit] == -1) {
trie[root][bit] = trie.size();
trie.push_back(vector<int>(2, -1));
}
root = trie[root][bit];
}
}
int get_max(vector<vector<int>> &trie, int nr) {
int ans = 0;
int root = 0;
for (int i = 30; i >= 0; i--) {
bool bit = (nr & (1 << i));
if (trie[root][!bit] != -1) {
ans += (1 << i);
root = trie[root][!bit];
} else if (trie[root][bit] != -1) {
root = trie[root][bit];
}
}
return ans;
}
int main() {
cin >> n;
int xr = 0;
for (int i = 1; i < n; i++) {
cin >> v[i];
xr1[i] = xr1[i - 1] ^ v[i];
}
for (int i = n - 1; i >= 1; i--) {
xr2[i] = xr2[i + 1] ^ v[i];
}
maxim1[1] = 0;
maxim2[n] = 0;
insert(trie1, xr2[1]);
for (int i = 2; i <= n; i++) {
maxim1[i] = get_max(trie1, xr2[i]);
insert(trie1, xr2[i]);
}
insert(trie2, xr1[n - 1]);
for (int i = n - 2; i >= 0; i--) {
maxim2[i] = get_max(trie2, xr1[i]);
insert(trie2, xr1[i]);
}
for (int i = 1; i <= n; i++) {
if (max(maxim1[i], maxim2[i - 1]) == n - 1) {
int xr1 = 0, xr2 = 0;
vector<int> fr(2 * n + 1);
fr[0] = 1;
ans[i] = 0;
for (int j = i - 1; j >= 1; j--) {
ans[j] = v[j] ^ ans[j + 1];
xr1 ^= v[j];
fr[ans[j]]++;
if (fr[ans[j]] >= 2) {
break;
}
}
for (int j = i; j < n; j++) {
ans[j + 1] = v[j] ^ xr2;
xr2 ^= v[j];
fr[ans[j + 1]]++;
if (fr[ans[j + 1]] >= 2) {
break;
}
}
int ok = 1;
for (int j = 0; j < n; j++) {
if (fr[j] != 1) {
ok = 0;
break;
}
}
if (1) {
for (int j = 1; j <= n; j++) {
cout << ans[j] << " ";
}
return 0;
}
}
}
}Problema cuvinte (medie-grea)
Se dau cuvinte formate doar din primele litere mici ale alfabetului englez și un șir , de numere naturale. Trebuie să se formeze cuvinte astfel încât oricare cuvânt să respecte următoarele proprietăți:
- Să aibă lungimea .
- Să fie format doar din primele litere mici ale alfabetului englez.
- Să nu existe , sau un cuvânt din cele , astfel încât cuvântul să fie prefix pentru cuvântul , sau să fie prefix pentru .
- Să nu existe , sau un cuvânt din cele , astfel încât cuvântul să fie prefix pentru cuvântul , sau să fie prefix pentru .
Soluție
Prima idee ar fi să sortam vectorul . Fie = în câte moduri putem alege primele cuvinte. Putem considera toate posibilitățile de a forma șirurile , iar abia apoi să vedem cum eliminăm pe cele care nu sunt bune. Cu alte cuvinte, fie primele cuvinte alese astfel încât să respecte condițiile impuse de problemă. Sunt în total moduri de a forma un set de șiruri cu primele cuvinte.
Observație
Nu există două cuvinte, și , astfel încât ambele să fie prefixe pentru .
Dacă ambele ar fi prefixe pentru , atunci fie este prefix pentru , fie invers, ceea ce este fals, pentru că noi am generat primele cuvinte optim.
Astfel dacă pentru fiecare cuvânt , , putem să scădem din numărul total de posibilități șirurile unde este prefix pentru , nu vom elimina două configurații la fel.
Observație
Nu există două cuvinte, unul provenit din cele date și celălalt () din primele astfel încât ambele să fie prefixe pentru . Dacă ambele sunt prefixe pentru , atunci fie este prefix pentru un cuvânt din cele , fie invers.
Deci, putem să fixam un cuvânt din cele date inițial și să eliminăm numărul de posibilități ca el să fie prefix pentru . Datorită observației, nu vom elimina o posibilitate dacă a fost eliminată deja în prima etapă.
În mod natural vom zice că din dp-ul nostru vom scădea în mod similar , unde = lungimea cuvântului , cu . Însă nu este adevărat, pentru că dacă avem două cuvinte și , unde este prefix pentru , atunci suma de mai sus va număra 2 configurații de două ori. Observăm că nouă ne trebuie practic doar acele cuvinte , pentru care nu există alt cuvânt , cu prefix pentru , iar .
Astfel putem parcurge direct pe Trie-ul cuvintelor. Dacă suntem la un nod , acesta este capătul unui cuvânt, iar , atunci putem scădea din dp-ul nostru și să oprim parcurgerea. Dacă suntem la un nod , acesta are lungimea egală cu , atunci scădem din dp și oprim parcurgerea.
Cu alte cuvinte, o soluție în este posibilă, unde . Putem optimiza soluția, observând că de fiecare dată putem face tranzițiile în . Soluția finală devine sau .
#include <bits/stdc++.h>
using namespace std;
const int mod = 1e9 + 7, N = 3e5 + 1;
struct Mint {
int val;
Mint(int x = 0) { val = x % mod; }
Mint(long long x) { val = x % mod; }
Mint operator+(Mint oth) { return val + oth.val; }
Mint operator*(Mint oth) { return 1LL * val * oth.val; }
Mint operator-(Mint oth) { return val - oth.val + mod; }
Mint fp(Mint a, long long n) {
Mint p = 1;
while (n) {
if (n & 1) {
p = p * a;
}
a = a * a;
n /= 2;
}
return p;
}
Mint operator/(Mint oth) {
Mint invers = fp(oth, mod - 2);
return 1LL * val * invers.val;
}
friend ostream &operator<<(ostream &os, const Mint &lol) {
os << lol.val;
return os;
}
};
int n, m, k;
vector<Mint> dp(N);
vector<int> x(N), depth(N), cnt1(N);
vector<vector<int>> trie(1, vector<int>(26, -1));
vector<bool> cnt(1);
Mint spm = 0;
Mint fp(Mint a, int n) {
Mint p = 1;
while (n) {
if (n & 1) {
p = a * p;
}
a = a * a;
n /= 2;
}
return p;
}
void insert(string a) {
int root = 0;
for (int i = 0; i < a.size(); i++) {
if (trie[root][a[i] - 'a'] == -1) {
trie[root][a[i] - 'a'] = trie.size();
trie.push_back(vector<int>(26, -1));
cnt.push_back(0);
}
root = trie[root][a[i] - 'a'];
}
cnt[root] = 1;
}
void dfs(int node, int lenx, int len) {
if (lenx == len) {
return;
}
if (cnt[node]) {
spm = spm + fp(k, lenx - len);
return;
}
for (int i = 0; i < 26; i++) {
if (trie[node][i] != -1) {
dfs(trie[node][i], lenx, len + 1);
}
}
}
void dfs1(int node, int len) {
depth[len]++;
if (cnt[node]) {
cnt1[len]++;
return;
}
for (int i = 0; i < 26; i++) {
if (trie[node][i] != -1) {
dfs1(trie[node][i], len + 1);
}
}
}
int main() {
cin.tie(0)->sync_with_stdio(0);
cin >> n >> m >> k;
for (int i = 1; i <= n; i++) {
string a;
cin >> a;
insert(a);
}
for (int i = 1; i <= m; i++) {
cin >> x[i];
}
sort(x.begin() + 1, x.begin() + 1 + m);
dp[1] = fp(k, x[1]);
Mint sm = 0;
dfs(0, x[1], 0);
dfs1(0, 0);
dp[1] = dp[1] - depth[x[1]];
dp[1] = dp[1] - spm;
for (int i = 2; i <= m; i++) {
dp[i] = dp[i - 1] * fp(k, x[i]);
sm = sm * fp(k, x[i] - x[i - 1]);
sm = sm + fp(k, x[i] - x[i - 1]);
dp[i] = dp[i] - dp[i - 1] * sm;
spm = spm * fp(k, x[i] - x[i - 1]);
for (int j = x[i - 1]; j < x[i]; j++) {
spm = spm + fp(k, x[i] - j) * cnt1[j];
}
dp[i] = dp[i] - dp[i - 1] * depth[x[i]];
dp[i] = dp[i] - dp[i - 1] * spm;
}
cout << dp[m];
}Problema cli (medie-grea)
Se dau cuvinte care trebuie tastate într-un terminal. Un cuvânt este considerat tastat dacă el va apărea în terminal cel puțin odată pe parcursul tastării. Avem două tipuri de operații la dispoziție: adăugăm un caracter la finalul șirul tastat deja, eliminăm un caracter de la finalul șirului (dacă nu este vid). Pentru fiecare , noi trebuie să aflam care este numărul minim de operații pentru a tasta exact cuvinte distincte dintre cele date. În momentul în care începem să tastăm un cuvânt, trebuie mereu să începem de la un șir vid , și să terminăm tastarea tot la un șir vid. Un exemplu de tastare corectă este: .
Ne vom folosi din nou de metoda programării dinamice, dar de data asta vom face dp direct pe trie. Astfel, fie = numărul minim de operații pentru a tasta cuvinte cu prefixul format din lanțul de la rădăcină la . Acum, pentru un nod fixat din trie-ul nostru, putem presupune că în momentul tastării vom începe mereu cu șirul format de la rădăcină la , în loc de . De exemplu, dacă cuvintele au prefixul abab, atunci noi vom presupune o succesiune validă de operații: . Putem deci face un rucsac pentru fiii nodului, = care e numărul minim de operații pentru a tasta cuvinte din primii fii. Pentru că prefixul necesită operații de adăugare și ștergere, vom începe -ul nostru cu operații deja făcute. Cu alte cuține, pentru a tasta 0 cuvinte vom face . În momentul în care trecem de la la avem 2 cazuri: fie nu luăm fiul respectiv în considerare, fie alegem șiruri pe care le vom tasta în operații.
for (int i = 1; i <= 26; i++) {
for (int k1 = 0; k1 <= min(sz[nod], k); k1++) {
dp1[i][k1] = min(dp1[i][k1], dp1[i - 1][k1]);
const auto nod2 = trie[nod][i - 1];
for (int k2 = 1; k2 <= k1 && nod2 != -1 && k2 < dp[nod2].size(); k2++) {
dp1[i][k1] =
min(dp1[i][k1], dp1[i - 1][k1 - k2] + dp[nod2][k2] - 2 * len);
}
}
}Problema constă în faptul că secvența de cod de mai sus rulează pentru fiecare nod din trie, ceea ce ar rezulta într-o complexitate de . Doar că, în practică soluția are complexitatea de . În momentul în care facem rucsac pe un arbore, este foarte important să fim atenți la memoria și la timpul consumate. Observăm faptul că cele două bucle merg până la , lucru ce îmbunătățește timpul de execuție considerabil. Puteți citi mai multe din soluția problemei Barricades, iar sursa completă o puteți vizualiza aici.
Probleme suplimentare
- intervalxor2 (Trie pe biți persistent. Puteți face queriurile și offline)
- xortree2 (Problemă ok cu trie pe biți)
- rps (Alt exemplu de dp pe trie)
- ratina (Lowest Common Ancestor pe trie)
- aiacupalindroame
- Facebook Search
- Perfect Security
- Collapsing Strings